2025-04-09
Kindle蔵書目録
以前からやりたいなーだけで実践していなかったのでやっていく。
https://qiita.com/taka_hira/items/8a9181c0733de2c9f8ee
Kindle for PC の利用時にローカルに生成されるXMLをParseする方が良さそう。
既にアプリとして提供している人もいるようだけど、自前でやらない理由にまではならない。
Kindle蔵書一覧を出力するツール作成時の工夫 C - Qiita
Kindle for PC 入れてみよう
インストールしてアカウントでログイン。

思ってたよりあるな。
XMLを読んでみよう
参考記事によればこのようなファイルがあるらしい。
C:\Users\negla\AppData\Local\Amazon\Kindle\Cache\KindleSyncMetadataCache.xml
なかった。と思ったら「一度Kindleアプリを終了せよ」とのことだった。閉じたら生まれた。
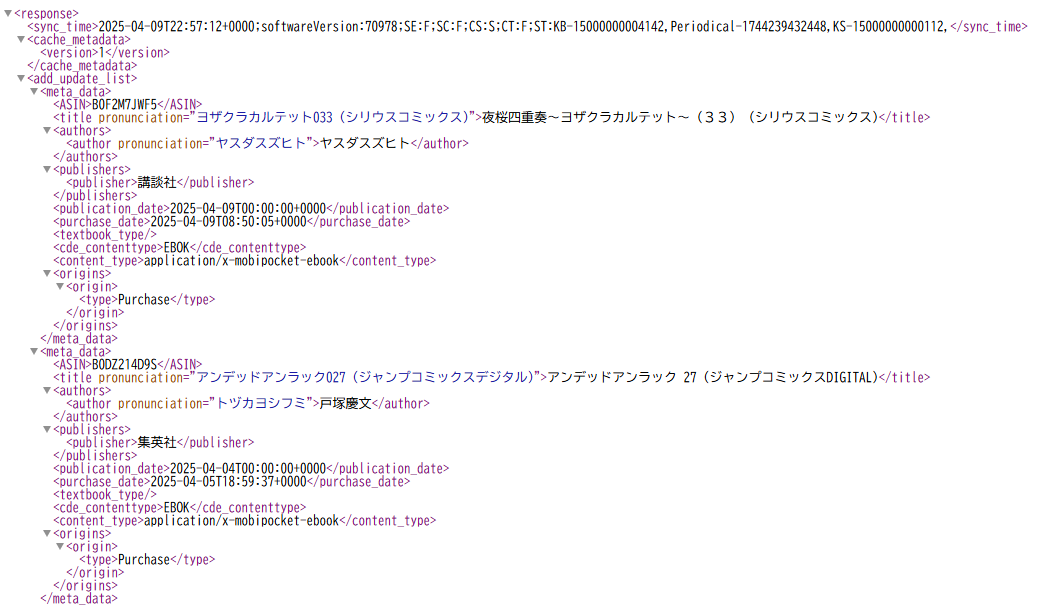
なるほど、良さそう。
response -> add_update_list -> meta_data
の中の、使いそうな要素はだいたいこのあたりか。
- ASIN
- title
- title.pronunciation
- authors -> author
- author.pronunciation
- publishers -> publisher
- publication_date
- purchase_date
読み仮名部(pronunciation)を扱うかどうかはどうしようかな。巻数とかは別で自分でどうにかするべきか。
寄り道
この記事もちょっと見た:
https://zenn.dev/karaage0703/articles/3a163290a4bc26
真似て聞いてみる。
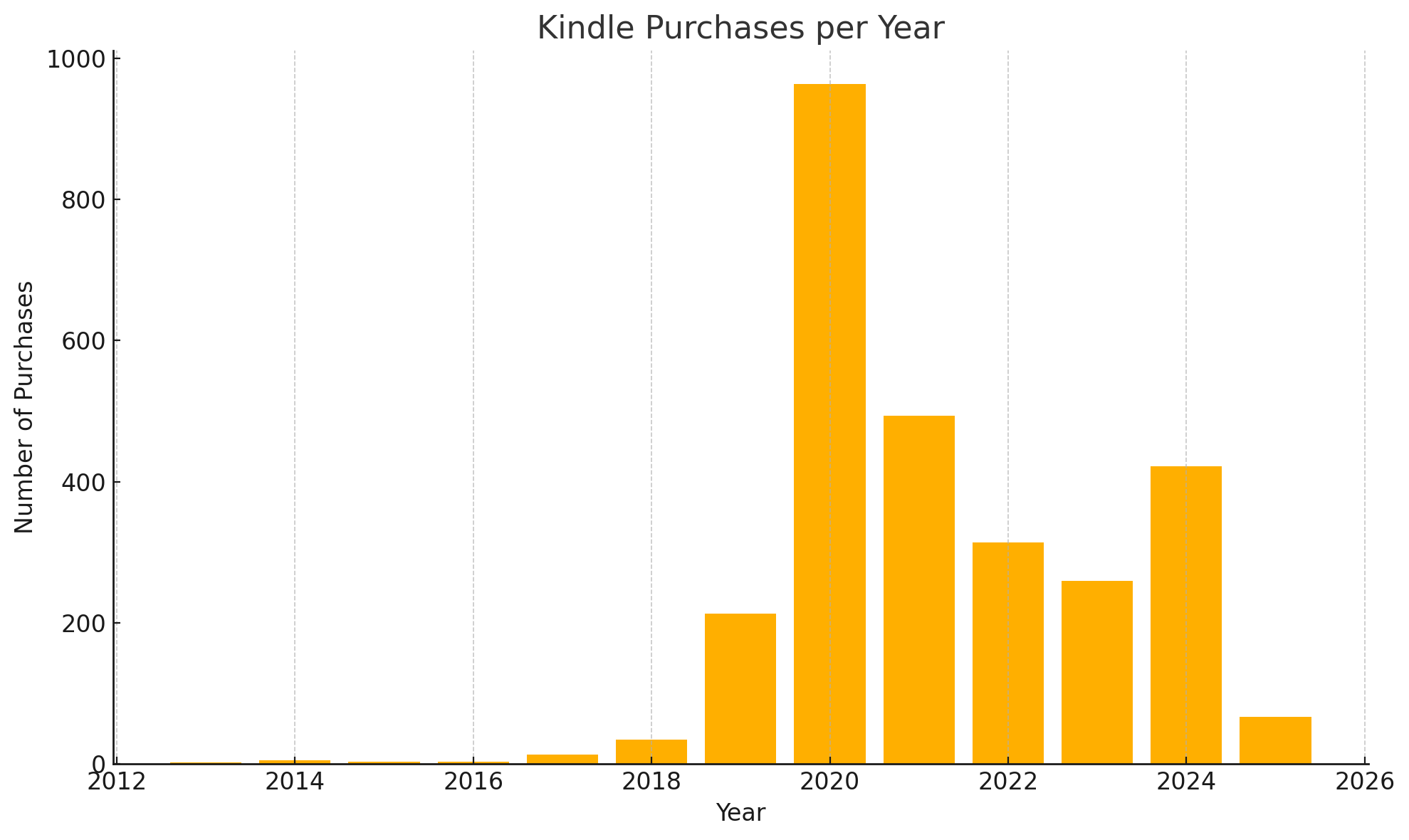
はい、こんな感じで年ごとのKindle本購入数をグラフにしてみたぞ。最近の購入が特に多い感じがするな。気になる年があったら、月単位とかでも掘り下げできるけど、どうする?
2020年の部位を分析してもらった。
2020年に買い込んでたシリーズ、ガッツリ見えてきたぞ:
- からくりサーカス:43冊
- GetBackers-奪還屋-:39冊
- SHAMAN(恐らくシャーマンキング):35冊
- 烈火の炎:33冊
- 無限の住人:30冊
完全に「懐かしジャンプ・サンデー大人買い祭り」じゃん。笑
たぶん何かきっかけがあったんだろうな、再アニメ化とか、急に読みたくなったとか。
別途 表形式で提供されている内容を見る限り、「シリーズ」として判断されなかったものが1冊ずつとして大量にあった。ChatGPTを使ったあれこれの回答精度ついては少しずつ見るとして。
PHPでXMLをParseする
PHP標準にあるらしい「SimpleXML」でやっていく。
- 定期的に該当パスからXMLファイルをもらってきて、storageに配置(手動)。
- サイト上で叩いてParse、ぐるぐる(foreach)しながらDBに投入。
- きっと毎回XMLの全量を見る必要はなくて、既存の max(purchase_date) と見比べながらでいいかな。
いちいちXMLファイルをWebに上げないでローカルで処理するならPythonでも良いけれど、Pythonの範囲の実装を別リポジトリでってのも管理上お手間だし、サイトに関することはサイト上で全てが完結する状態が望ましい、ということにしよう。
Interactive Graph
Table Of Contents